Projeto de Controladores
Aula ministrada em 30/09/2024. Continuação da aula de 23/09/2024.
Embasamento teórico sobre Controladores com Ação Derivativa
- Ação Derivativa (Derivador Puro? Simulações, cuidados e atenção);
- Ação Derivativa na presença de sinal ruidoso (Aula de 11/11/2022);
- Teoria à respeito de Compensador por Avanço de Fase (Lead) (Aula de 02/06/2021).
Projeto de PD
Recuperando seção de trabalho anterior:
xxxxxxxxxx>> pwd % verificando pasta atual onde dados estão gravadosans = '/Volumes/DADOS/Users/fpassold/Documents/UPF/Controle_2/2024_2'>> load planta % carregando dados da seção de trabalho anterior>> diary aula_30092024.txt % iniciando registro desta aulaLembrando da eq. da planta:
xxxxxxxxxx>> zpk(G) 20 ------------------ (s+10) (s+4) (s+1) Continuous-time zero/pole/gain model.Eq. genérica do PD:
onde: ganho genérico do controlador (definido com auxílio do RL); zero do controlador PD -- incógnita atual.
Seguem esboços de RL para diferentes opções de locais para o zero do PD. Para ver opções (casos semelhantes, recomenda-se verificar o item "Projeto de PD (Aula de 03/10/2019").
Opções:
- Opçao 1: : mas neste caso teremos um pólo de MF real muito próximo do eixo , atrasando muito a resposta do sistema;
- Opção 2: : resulta um pólo de MF real dominante mais afastado do eixo Na prática, seria a melhor opção.
- Opção 3: (cancelando o 2o-pólo mais lento da planta). Resulta num sistema em MF de 2a-ordem (redução de complexidade do sistema).
- Opção 4: (cancelando o pólo mais lento da planta). Resulta num sistema em MF de 2a-ordem e mais rápido que opção 3. Ao menos teoricamente, supondo que os pólos estejam realmente em , e que o sistema não possua não linearidades).
PD Opção 2
Neste caso: . Arbitrando um local gemétrico intermediário:
xxxxxxxxxx>> (1+4)/2ans = 2.5>> PD2 = tf( [1 2.5], 1)PD2 = s + 2.5 Continuous-time transfer function.>> ftma_PD2 = PD2*G;>> zpk(ftma_PD2) 20 (s+2.5) ------------------ (s+10) (s+4) (s+1) Continuous-time zero/pole/gain model.>> rlocus(ftma_PD2)>> hold on; sgrid(zeta,0)>> [K_PD2,polosMF]=rlocfind(ftma_PD2)Select a point in the graphics windowselected_point = -6.3768 + 8.6378iK_PD2 = 4.509polosMF = -6.3444 + 8.6372i -6.3444 - 8.6372i -2.3112 + 0iObtemos o RL abaixo, já ressaltando pontos de sintonia e outros detalhes:
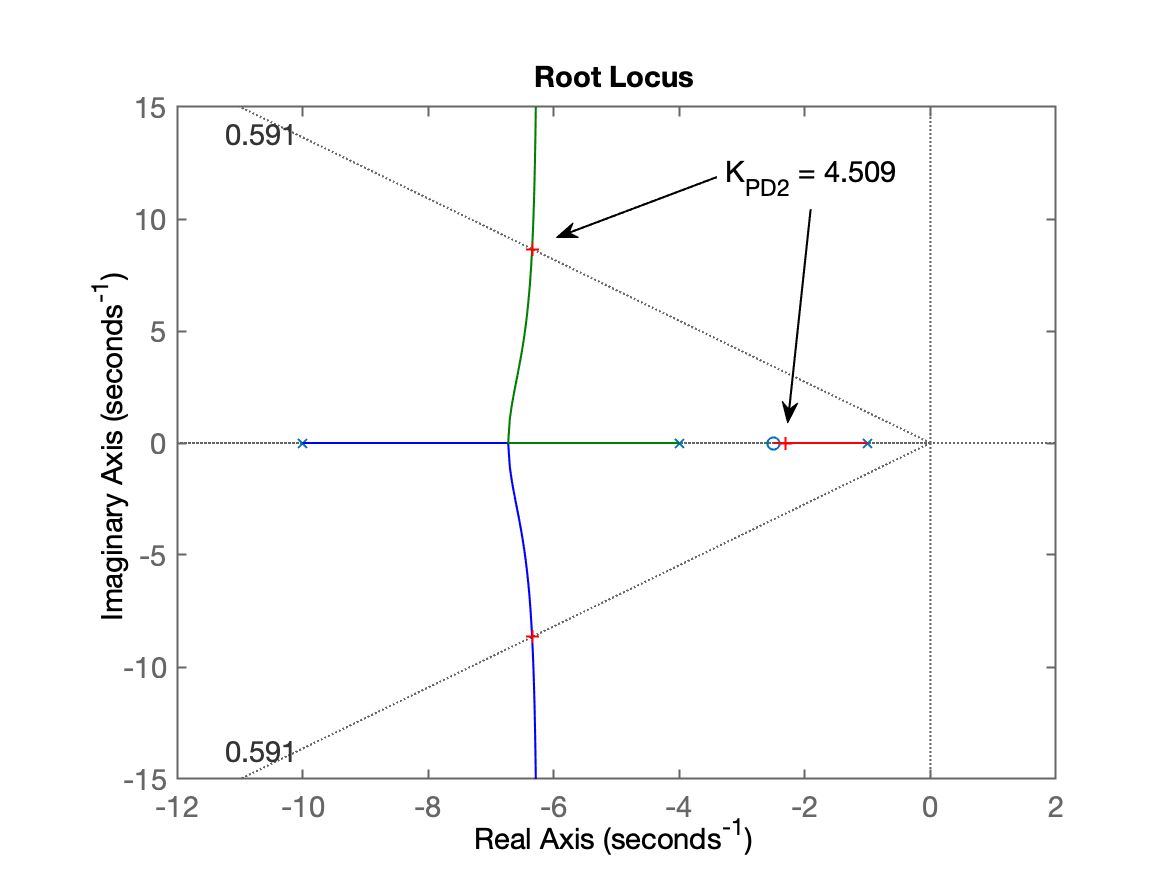
xxxxxxxxxxftmf_PD2=feedback(K_PD2*ftma_PD2, 1); % fechando a malhafigure; step(ftmf_PD2, ftmf)Obtemos a seguinte resposta ao degrau para este PD, comparando sua resposta com controlador Porporcional realizado na aula de 09/09/2024.
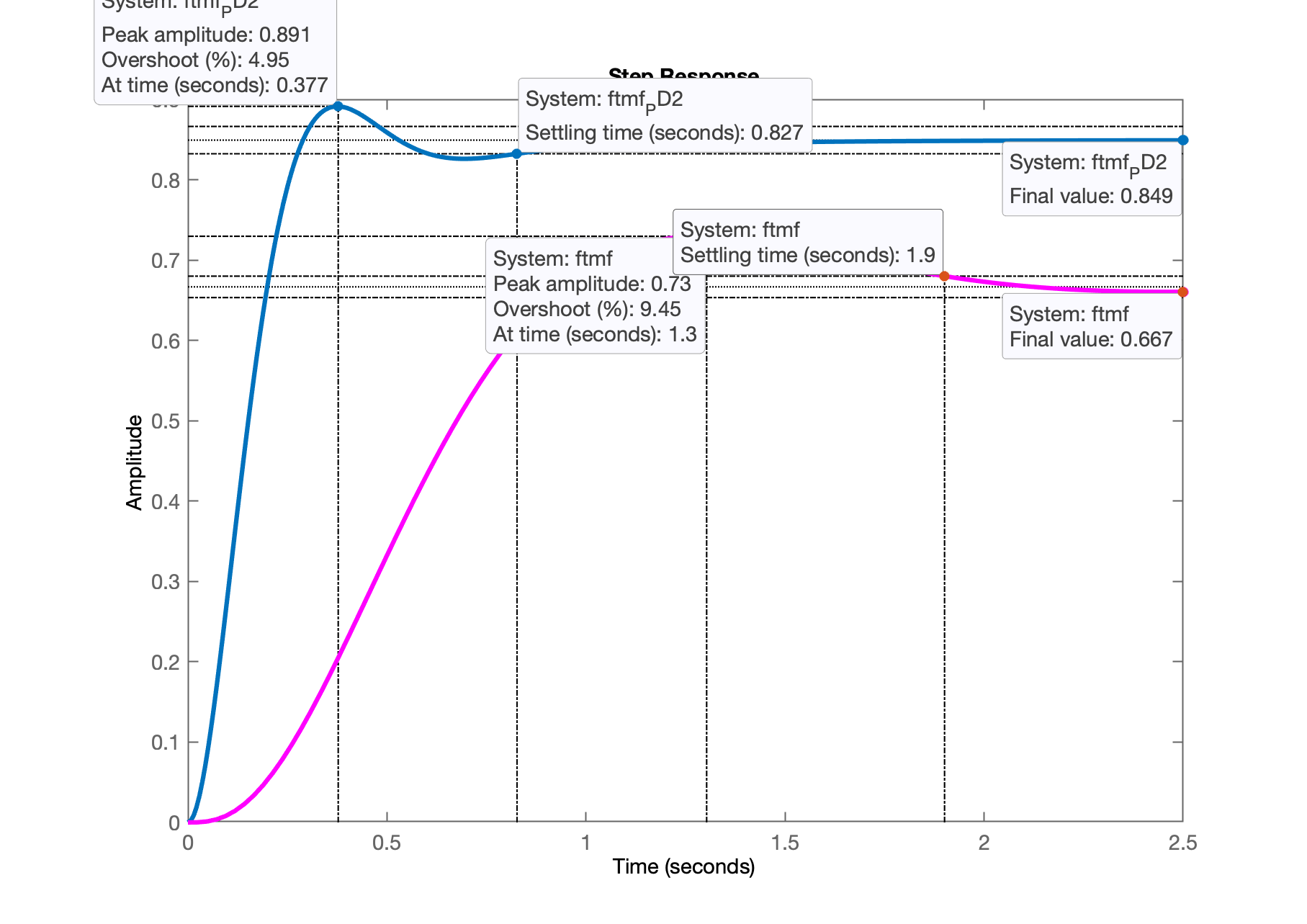
Comentários:
- Poderia ser aumentado o ganho deste PD, já que o ficou abaixo dos 10% em relação à entrada degrau (implica já que a referência é entrada degrau unitário, então );
- Mas é mais interessante deslocar o zero do PD para mais próximo do pólo da planta em (revisar RL), o que resultaria num pólo de MF real dominante mais afastado do eixo (mais rápido).
Projeto do PD (pção 4)
O PD mais rápido, em teoria, seria obtido fazendo o zero do PD propositalmente cancelar o pólo mais lento da planta em .
xxxxxxxxxx>> PD4 = tf( [1 1], 1)PD4 = s + 1 Continuous-time transfer function.>> ftma_PD4=PD4*G;>> zpk(ftma_PD4) 20 (s+1) ------------------ (s+10) (s+4) (s+1) Continuous-time zero/pole/gain model.>> ftma_PD4aux=minreal(ftma_PD4);>> zpk(ftma_PD4aux) 20 ------------ (s+10) (s+4) Continuous-time zero/pole/gain model.>> figure; rlocus(ftma_PD4)>> hold on; sgrid(zeta,0)>> ylim([-15 15]) % usando mesmos limites que RL obtido anteriormente (para comparação visual)>> [K_PD4,polosMF]=rlocfind(ftma_PD4)Select a point in the graphics windowselected_point = -7.0071 + 9.5666iK_PD4 = 5.026polosMF = -7 + 9.5666i -7 - 9.5666i -1 + 0iRL obtido para este controlador:
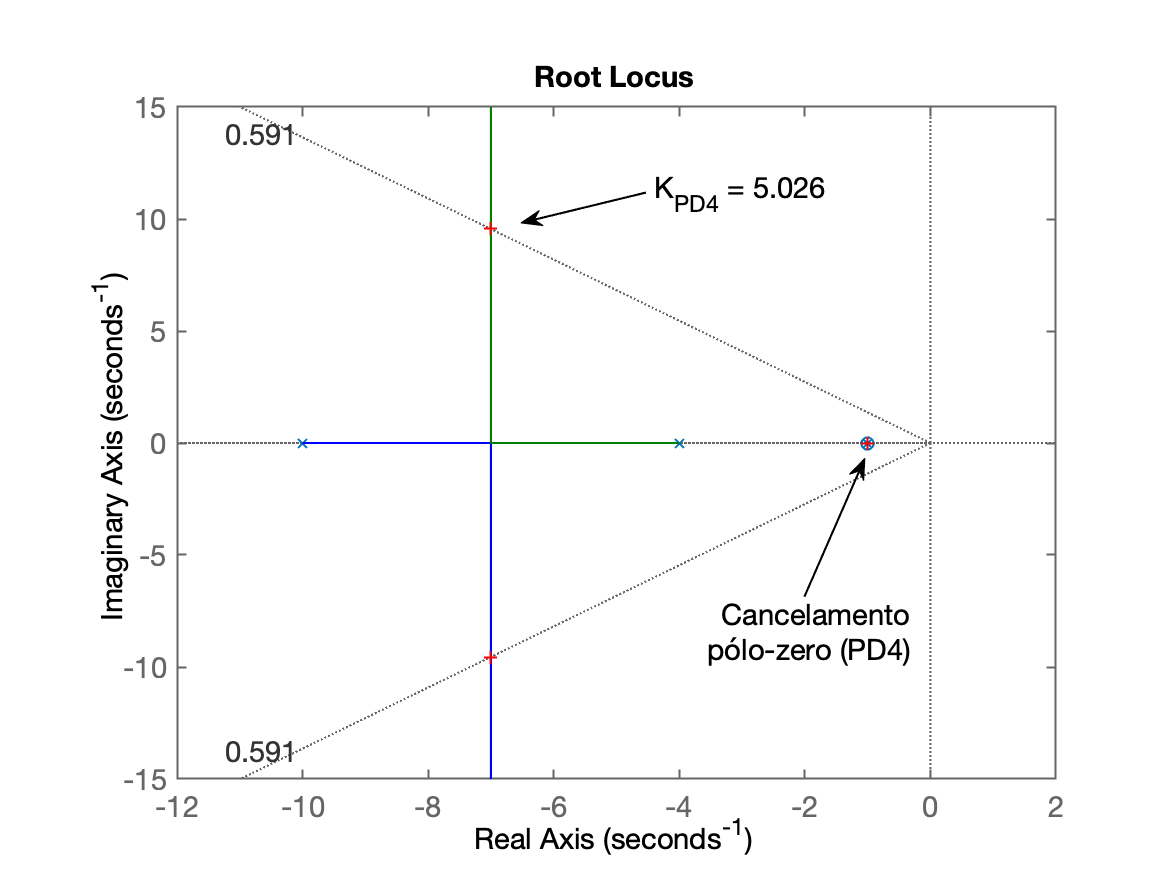
xxxxxxxxxx>> % fechando a malha>> ftmf_PD4=feedback(K_PD4*ftma_PD4, 1);>> figure; step(ftmf_PD2, ftmf_PD4)>> legend('PD2', 'PD4')Resposta em MF para entrada degrau, comparada com PD da opção 2:
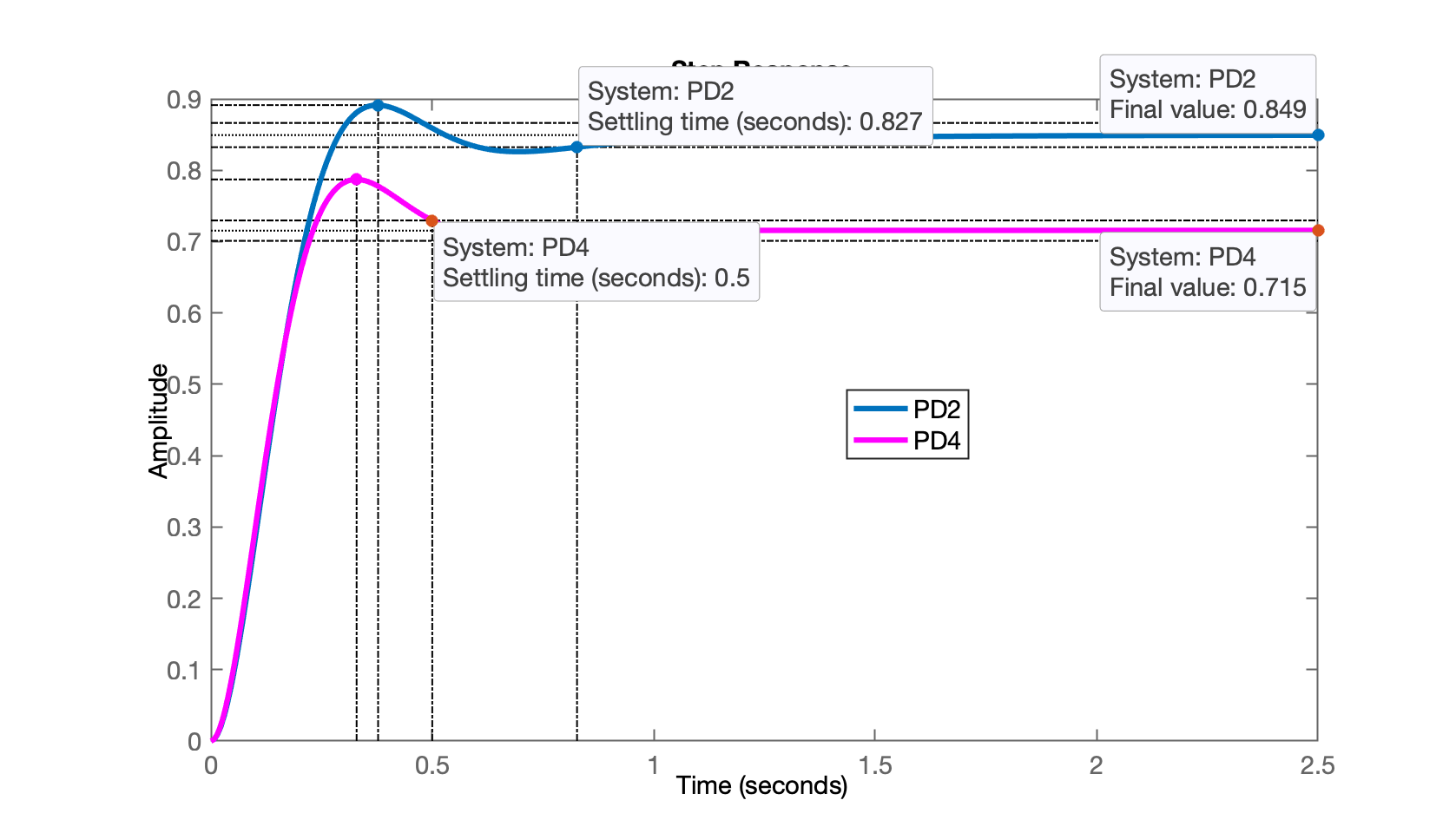
Comentários:
Pode-se aumentar ainda mais o ganho do PD4, neste caso, acompanhando o que aconteceria no RL, vamos perceber que reduzimos o valor de (parte imaginária dos pólos complexos de MF "sobe"), mas se manteria no mesmo valor, já que a parte real dos pólos de MF não varia de valor. Mas o que importa neste caso é que o erro de regime permante deve ser sensivelmente reduzido (é o que normalmente acontece quando se eleva o ganho para sistemas tipo 0 -- ver Teoria do Erro);
Porém note que o erro do PD4 é maior que o erro do PD2. O PD4 pode ser mais rápido que o PD2, mas com o ganho
K_PD4no valor que está, resulta num erro muito maior:xxxxxxxxxx>> erro_PD4= ((1-dcgain(ftmf_PD4))/1)*100erro_PD4 =28.466>> erro_PD2= ((1-dcgain(ftmf_PD2))/1)*100erro_PD2 =15.069
Observação final:
Para próxima aula, a idéia é usar o "App Control System Desginer" do Matlab, para facilitar e acelerar o projeto de controladores. Neste caso, podemos melhorar o PD2, testando seu zero mais próximo de , para intencionalmente fazer o pólo de MF real dominante se afastar ainda mais do eixo (menor tempo de resposta, menor ) e ainda encontrar um valor de ganho elevado que permita fazer (10% de overshoot em relação à entrada degrau). E assim estaríamos projetando o melhor PD prático para este tipo de sistema.
Encerrando atividades nesta aula:
xxxxxxxxxx>> save planta>> diary off>> quit🌊 Fernando Passold 📬 ,