Montagem dos Conjuntos de Treinamento das RNs
Montagem dos Conjuntos de Treinamento das RNsReferência3.5 Montagem dos Conjuntos de Treinamento das Redes NeuraisRede 1: Classificação do Estado Físico:
Referência
- Passold, Fernando, Cap 3.5 Montagem dos Conjuntos de Treinamento das Redes Neurais, pp 82—84, In: Sistema especialista hibrido em anestesiologia para pacientes criticos/problematicos, Dissertação (Mestrado), Preograma de Pós-Graduação em Engenharia Elétrica, UFSC, 209 p., 1995, URL: https://repositorio.ufsc.br/xmlui/handle/123456789/111563.
3.5 Montagem dos Conjuntos de Treinamento das Redes Neurais
Existia uma base de dados com 774 pacientes críticos/problemáticos (PROB.DBF) no momento da realização da dissertação. Esta base foi dividida em duas bases menores: (PROB1.DBF e PROB2.DBF). Estas bases foram convertidas até um formato conveniente (arquivos .NNL gerados pela rotina GERNNI2) para treinamento das redes neurais. Posteriormente estes dados foram tratados por um programa editor EDITA. A rotina GERNNI2 realiza um primeiro filtro nos dados de saída para algumas redes neurais, evitando padrões com todos os neurônios inativos para redes em que um PE no minimo sempre deva estar ativado. O programa EDITA facilita a organização dos conjuntos de treinamento (treino e teste) das redes neurais, permitindo que se:
- evite sequências repetidas de padrões de saída para as redes;
- randomize o conjunto de treinamento;
- elimine um padrão;
- mova um padrão ou vários para uma outra posição dentro do arquivo
.NNI; - verifique a sequência dos padrões de saída sendo preparados;
- vizualize um histograma com a freqüência de ativação dos PES de saída.
Tomou-se o cuidado de formar conjuntos de treinamento (treino e teste) com fichas de pacientes distintas, sequências não repetidas de padrões de saída e distribuição semelhante entre seus padrões de saída (a figura 32 mostra um exemplo do conjunto de treino e teste preparado para a rede 1).
| Figura 32. Conjuntos de treinamento para a rede 1. |
|---|
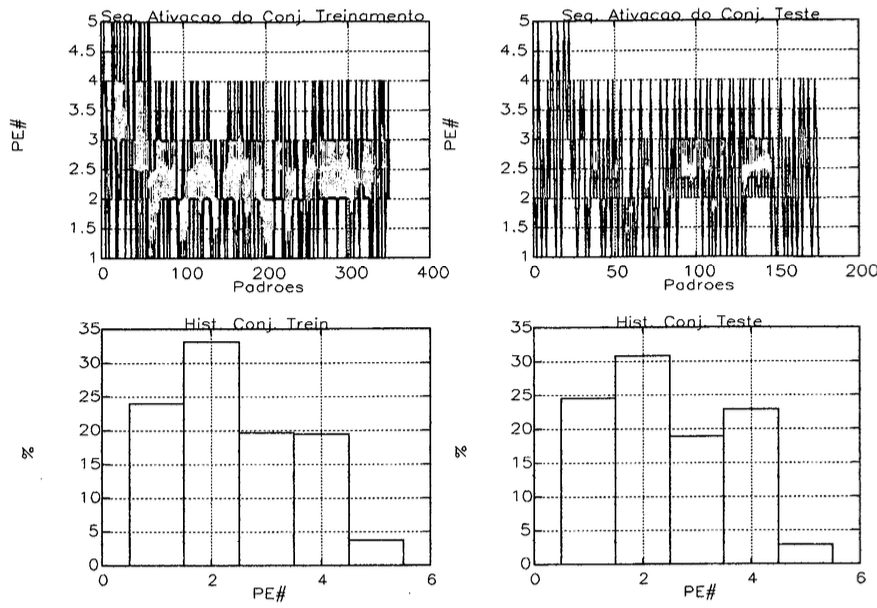 |
A parte inferior da figura 32 mostra o histograma (frequência) com que certos neurônios de saída eram ativados para determinada rede (esta rede em particular (Rede 1: Classificação do Estado Físico (do paciente)) possuia 5 neurônios na sua camada de saída).
Uma sequência repetida de padrões iguais pode levar a rede a viciar num certo padrão durante o seu treinamento dificultando o mapeamento dos outros padrões. A distribuição similar de padrões entre o conjunto de treino e teste de uma rede neural evita interpretações errôneas na verificação do desempenho de uma rede.
A maior ocorrência de um certo padrão no conjunto de teste em detrimento de sua baixa ocorrência no conjunto de treino, pode induzir erroneamente para um baixo desempenho no treinamento da rede. A rede pode coincidentemente não ter aprendido a generalizar tão bem um padrão que justamente aparece em maior frequência no conjunto utilizado para teste, baixando o valor computado para o desempenho da rede. Isto pode ser minimizado se a distribuição de padrões entre o conjunto de treino e teste for similar.
Rede 1: Classificação do Estado Físico:
Estrutura da rede neural escolhida:
| Ensaio escolhido | 17 | Taxa de aprendizado | 0,05 |
|---|---|---|---|
| Número de PEs na Camada de Entrada | 298 | Termo Momentum | 0,3 |
| Número de PEs na Carnada Intermediária | 8 | Ruído | 0,0001 |
| Número de PEs na Camada de Saída | 5 | Número de Ciclos | 34650 |
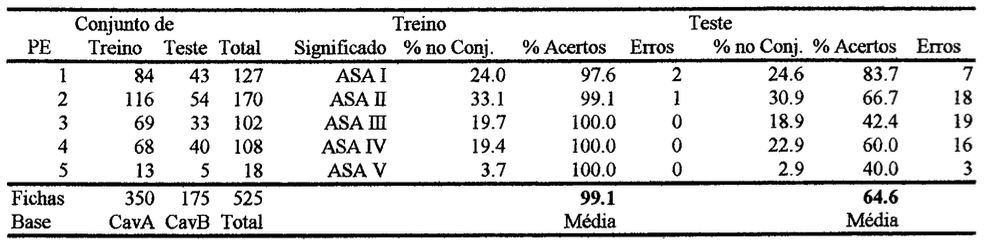
A tabela à seguir mostra os resultados obtidos para treinamento da rede 1, ensaio 17:
Segue para: 3.6 Treinamento das Redes Neurais.
13/05/2025