Principais Funções Transferência no Keras
Principais Funções Transferência no KerasPrincipais Funções de Ativação Disponíveis no KerasLinear (reta)Sigmóide (Sigmoid)Tangente Hiperbólica (Tanh)ReLU (Rectified Linear Unit)Leaky ReLUSeLU (Scaled Exponential Linear Unit)SoftPlusSoftSignSwishExponencialELU (Exponencial Linear Unit)GeLU (Gaussian Error Linear Unit)SoftMaxCódigo para Plotar $f(x)$ e $f'(x)$ExplicaçãoMelhorando o código anterior para outras transfer functionsO que foi alterado?Ocultando mensagens de Warnings no KerasSolução: Suprimir os logs do TensorFlowExplicação dos Níveis de Log
É possível gerar um gráfico usando Matplotlib para exibir tanto a função de ativação quanto sua derivada .
O Keras fornece diversas funções de ativação pré-implementadas na sub-biblioteca keras.activations, mas a maioria delas não expõe diretamente a derivada. No entanto, é possível calcular a derivada manualmente usando tensorflow.gradients ou autodiff do TensorFlow.
É possível gerar um gráfico usando Matplotlib para exibir tanto a função de ativação quanto sua derivada . Vamos tentar mostrar as funções, suas equações e gráficos correspondentes.
Principais Funções de Ativação Disponíveis no Keras
O Keras inclui as seguintes funções de ativação, que podem ser passadas como strings:
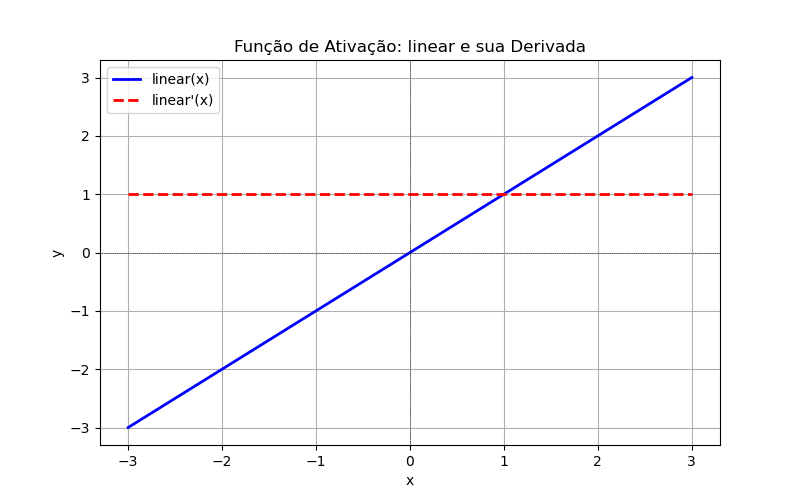
Linear (reta)
'linear'- Equação:
- Faixa de Entrada:
- Faixa de Saída:
- Derivada: (inclinação da reta)
Sigmóide (Sigmoid)
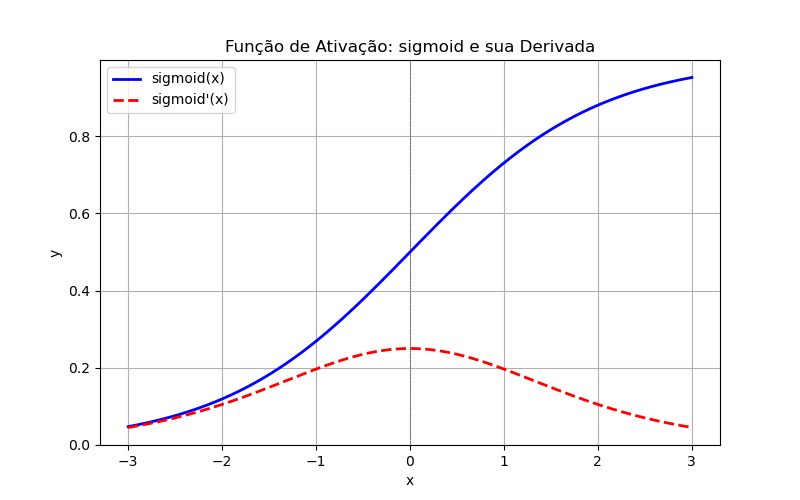
'sigmoid': Função Sigmóide (Sigmoid)Equação:
Faixa de Entrada:
Faixa de Saída:
Derivada:
Uso: principalmente em problemas de classificação binária, onde queremos prever uma probabilidade entre 0 e 1.
Vantagens:
- Interpretação clara → A saída pode ser interpretada como uma probabilidade direta.
- Suavidade → A função é contínua e diferenciável em todos os pontos.
Desvantagens:
Vanishig Gradient Problem 🚨
- Para valores muito grandes (positivos ou negativos), os gradientes ficam muito pequenos, dificultando o treinamento de redes profundas.
- Isso ocorre porque as derivadas da Sigmoid tendem a zero em valores extremos.
- Sua derivada é não-monotônica, isto é, pode assimir o mesmo valor para entradas negativas ou positivas.
Não é centrada em zero ⚠️
- A saída da Sigmoid sempre é positiva (0 a 1). Isso pode levar a gradientes menos eficientes, pois os pesos podem levar mais tempo para convergir.
Computacionalmente mais cara 💰
- A Sigmoid usa a função exponencial, o que pode ser um pouco mais lento do que ReLU ou Leaky ReLU.
Tangente Hiperbólica (Tanh)
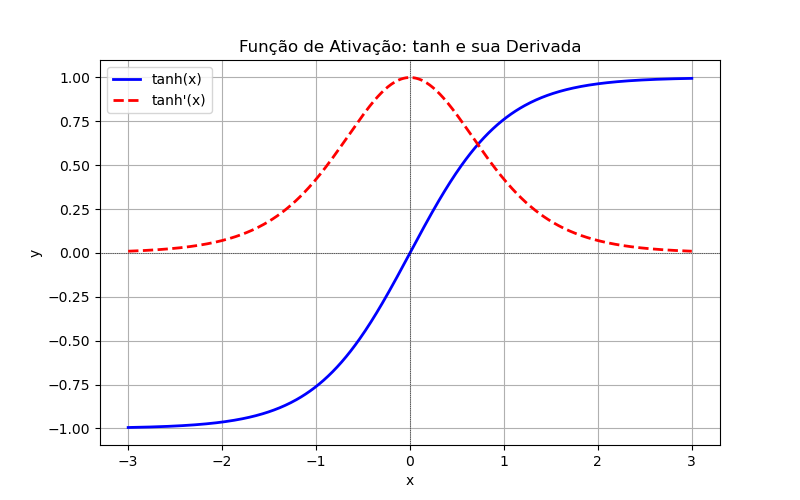
'tanh': Função Tangente Hiperbólica (Tanh)Equação:
Faixa de Entrada:
Faixa de Saída:
Derivada:
Comparação entre sigmoid tanh:
Característica sigmoid(x)tanh(x)Intervalo de Saída Simetria Não centrada em zero Centrada em zero Vanishing Gradient SIm (problema grave) Sim (mas menos severo) Uso recomendado Classificação binária Camadas ocultas em RNs
ReLU (Rectified Linear Unit)
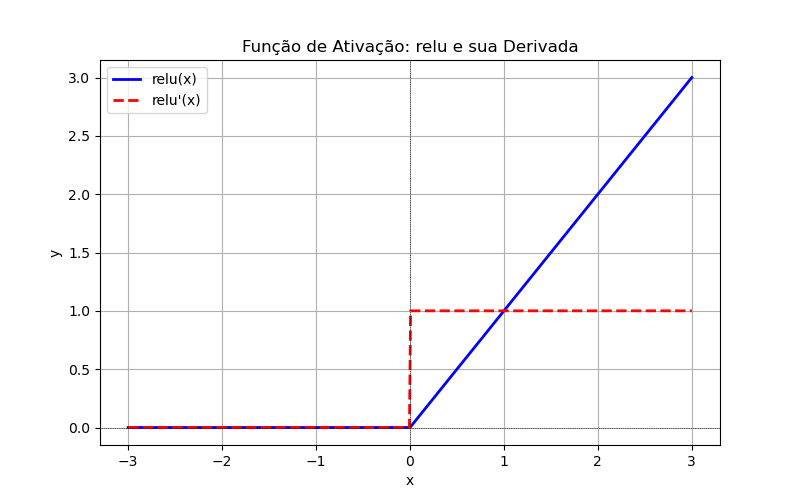
'relu': Rectified Linear Unit, por exemplo:xfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Densemodel = Sequential([Dense(64, activation='relu', input_shape=(20,)),Dense(10, activation='softmax') # Última camada para classificação multiclasse])Equação: , ou:
Faixa de Entrada:
Faixa de Saída:
Derivada:
Uso:
- Redes neurais profundas (DNNs, CNNs, RNNs, Transformers, etc.)
- Redes convolucionais (CNNs) para visão computacional
- Redes recorrentes (RNNs/LSTMs), embora outras funções como tanh sejam comuns em algumas arquiteturas
- Redes totalmente conectadas (MLPs, Deep Learning geral)
Vantagens:
Treina redes profundas melhor que sigmoid e tanh.
- A ReLU permite gradientes mais fortes e propagação mais eficiente do erro em redes profundas.
- A ReLU se tornou padrão porque ajuda redes neurais a "aprender mais rapidamente" do que funções como sigmoid ou tanh.
Não sofre com o problema de Vanishing Gradient (quase sempre)
- Diferente da sigmoid e da tanh, a derivada da ReLU é 1 para $, evitando gradientes muito pequenos.
Computacionalmente eficiente 💨
- Apenas uma comparação e um máximo são necessários para calcular a ReLU.
Introduz esparsidade na rede
- Como muitos neurônios ficam "desativados" (saída = 0), isso melhora a eficiência computacional e evita overfitting.
Desvantagens:
Problema do "Neurônio Morto" 🚨
- Se um neurônio recebe um grande gradiente negativo, ele pode parar de ativar permanentemente ( para sempre).
- Isso pode acontecer se muitos pesos forem inicializados negativamente ou devido a um alto learning rate.
- Solução? → Use Leaky ReLU ou Parametric ReLU (veja abaixo).
Não é centrada em zero ⚠️
- Para , os valores são sempre positivos, podendo levar a desequilíbrios no aprendizado.
Pode ser instável em algumas redes
- Se os pesos forem mal inicializados, alguns neurônios podem parar de aprender (por conta do "neurônio morto").
Requer: inicialização dos pesos for bem feita (ex: He Initialization).
Leaky ReLU
activation=LeakyReLU(alpha=0.01)O Keras não aceita
leaky_relucomo string na ativação, então deve-se passar a função manualmente, por exemplo:xxxxxxxxxxfrom tensorflow.keras.layers import Densefrom tensorflow.keras.activations import linearfrom tensorflow.keras.layers import LeakyReLUlayer = Dense(10, activation=LeakyReLU(alpha=0.01)) # # Alpha padrão = 0.3ou:
xxxxxxxxxxfrom tensorflow.keras.layers import LeakyReLUmodel = Sequential([Dense(64),LeakyReLU(alpha=0.01), # Define o "leak" para valores negativosDense(10, activation='softmax')])Equação: , onde é uma pequena constante (e.g., 0.01)
Faixa de Entrada:
Faixa de Saída:
Derivada:
< Curvas >
SeLU (Scaled Exponential Linear Unit)
'selu': (Scaled Exponential Linear Unit)Equação: onde e são constantes escalares, constantes fixas para garantir a normalização da ativação:
Obs: Isso faz com que a SeLU auto-normalize os valores durante o treinamento, garantindo que os dados se mantenham com média zero e variância constante.
Faixa de Entrada:
Faixa de Saída:
Derivada:
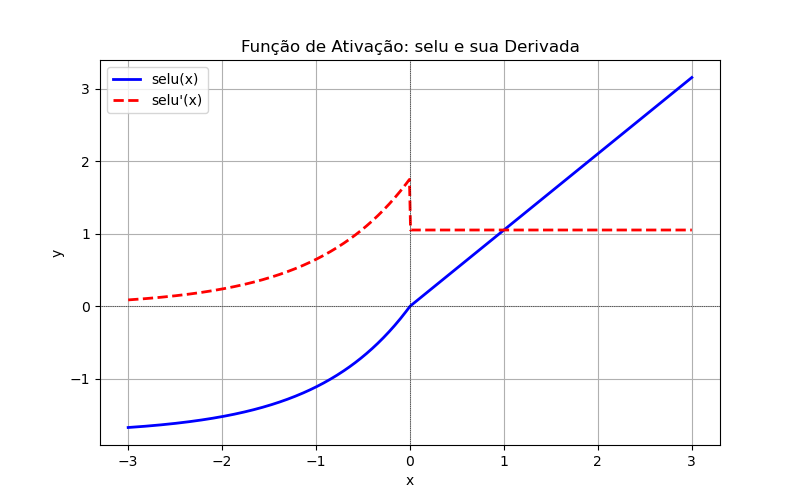
Proposta para permitir que redes neurais treinem de forma autônoma e robusta, mantendo a normalização dos dados sem precisar de Batch Normalization.
Vantagens:
Auto-normalização
- Mantém a média próxima de zero e a variância estável, reduzindo a necessidade de Batch Normalization.
Evita o problema do "neurônio morto"
- Diferente da ReLU, a SeLU tem um pequeno valor negativo para , evitando que neurônios parem de aprender.
Acelera o treinamento
- Por manter a normalização interna, SeLU pode levar a convergência mais rápida que ReLU.
Boa para redes profundas
- Especialmente eficaz em redes feedforward profundas.
Desvantagens:
Funciona melhor com inicialização específica (He Initialization Modificada)
SeLU funciona melhor com inicialização LeCun normal:
xxxxxxxxxxfrom tensorflow.keras.initializers import lecun_normalinitializer = lecun_normal()ou:
xxxxxxxxxxfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Densemodel = Sequential([Dense(64, activation='selu', kernel_initializer='lecun_normal', input_shape=(20,)),Dense(10, activation='softmax')])
Requer uma arquitetura específica
- SeLU foi projetada para redes densas profundas.
- Em CNNs e RNNs, pode não ser tão eficiente quanto ReLU ou Leaky ReLU.
Pode explodir ou morrer em certos casos
- Se os hiperparâmetros não forem bem ajustados, os valores podem divergir ao longo do treinamento.
SeLUs Outras funções:
Função Características Problemas Resolvidos ReLU Simples e eficiente, mas sofre com neurônios mortos. Leaky ReLU Pequeno valor negativo para Evita neurônios mortos, mas não auto-normaliza. ELU para Suaviza valores negativos, mas precisa de mais cálculos. SeLU Auto-normalização + pequeno leak negativo Mantém a média e variância constantes, acelerando o treinamento. Uso:
- Em redes densas profundas (MLPs com muitas camadas).
- Se quiser eliminar a necessidade de Batch Normalization.
- Se estiver enfrentando problemas de vanishing/exploding gradient.
- Quando quiser acelerar a convergência do treinamento.
SoftPlus
'softplus'Equação:
- Para grandes valores de (Aproxima-se da ReLU para ).
- Para valores negativos de (Permite pequenos valores negativos em vez de zero).
Faixa de Entrada:
Faixa de Saída:
Derivada: (diferenciável em qq ponto).
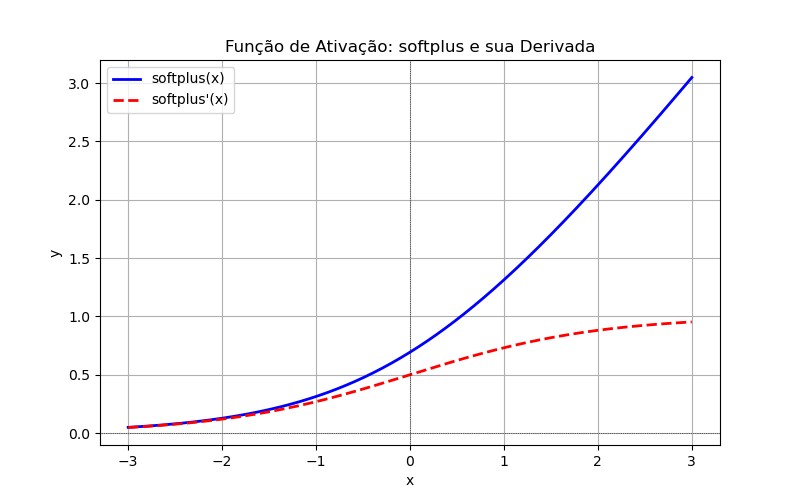
A Softplus é uma função de ativação que suaviza a ReLU ao substituir o corte brusco em por uma curva suave.
Vantagens:
Diferenciável em todos os pontos
- Ao contrário da ReLU, que tem uma descontinuidade na derivada em , Softplus é suave.
Evita "neurônios mortos"
- Diferente da ReLU, que pode zerar valores negativos, a Softplus nunca retorna exatamente zero, evitando o problema de neurônios mortos.
Boa para propagação do gradiente
- Sua derivada é a mesma da função sigmoid: .
Isso mantém um gradiente estável mesmo para valores negativos.
Melhor que a ReLU para algumas redes probabilísticas
- Em redes bayesianas e modelos estatísticos, é útil porque seu comportamento é próximo de funções logarítmicas.
Desvantagens:
Mais cara computacionalmente
- O cálculo de é mais pesado que o simples da ReLU.
Pode saturar para valores negativos muito baixos
- Para , a saída da Softplus é quase zero, causando o problema de vanishing gradient semelhante ao da função sigmoid.
ReLU ainda é mais popular para deep learning
- Em CNNs e redes profundas, ReLU é mais eficiente e amplamente utilizada.
SoftSign
'softsign'Equação: Essa função mapeia qualquer valor de entrada para o intervalo de forma suave, semelhante à tangente hiperbólica (tanh), mas com uma transição mais lenta para valores grandes de .
- Para pequenos valores de (próximos da origem), se comporta como uma função linear.
- Para grandes valores de , ela cresce mais lentamente que tanh, reduzindo o problema de saturação.
Faixa de Entrada:
Faixa de Saída:
Derivada:
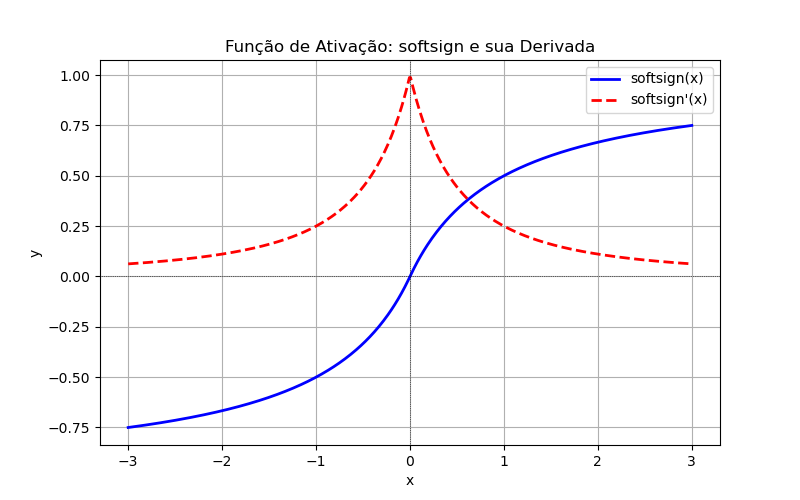
Vattagens:
Menos propensa a saturação extrema
- Ao contrário da sigmoid e tanh, a Softsign cresce mais lentamente, o que reduz o risco de vanishing gradient.
Mais suave do que ReLU e Softplus
- Como é contínua e diferenciável em todos os pontos, evita descontinuidades como as da ReLU.
Evita explosão de gradiente
- Como cresce mais devagar para valores grandes, pode ser mais estável do que tanh em redes profundas.
Desvantagens:
Mais lenta para grandes valores de xx
- Para , Softsign se aproxima de muito devagar. Isso pode retardar o aprendizado em certos cenários.
Menos popular que tanh e ReLU
- Como a tanh é bem estudada e a ReLU tem desempenho melhor em redes profundas, a Softsign é usada com menos frequência.
Pode sofrer com gradientes pequenos
- Em redes muito profundas, a Softsign ainda pode sofrer de vanishing gradient, embora menos que a sigmoid.
Uso:
- Em redes que precisam de uma função suave e diferenciável.
- Quando a saturação da tanh e sigmoid for um problema.
- Em alguns modelos de redes profundas que exigem estabilidade.
Comparando com funções similares:
Função Equação Características Sigmoid Mapeia para , usada em probabilidades,
mas sofre com vanishing gradient.Tanh Mapeia para ,
Melhor que sigmoid para redes profundas,
mas ainda pode saturar.Softsign Suave, menos propensa a saturação, mas cresce devagar. ReLU Simples e eficiente, usada em redes profundas, mas pode ter neurônios mortos. Softplus Suaviza a ReLU, diferenciável em todos os pontos,
mas computacionalmente mais cara.
Swish
'swish'(no TensorFlow 2.2+) Desenvolvida pelo Google.Equação: , onde é a função sigmóide e é um parâmetro aprendido ou fixo, ou:
- para , a função se aproxima de zero (como a sigmoidal);
- para , a função cresce linearmente (sem saturação, como a ReLU);
- Ao contrário da ReLU, a Swish permite valores negativos, o que pode ajudar no aprendizado.
Faixa de Entrada:
Faixa de Saída:
Derivada:
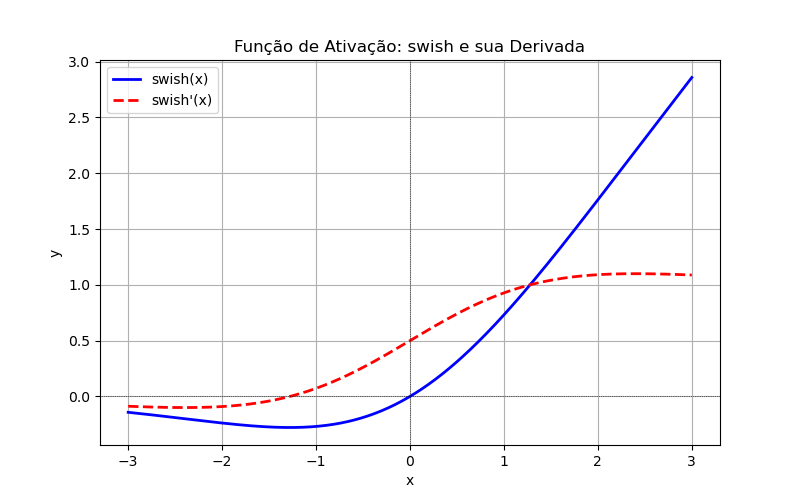
Vantagens:
Suavidade e continuidade
- Diferente da ReLU, a Swish é totalmente diferenciável em todos os pontos.
Evita o problema de neurônios mortos
- A ReLU pode zerar neurônios para sempre (), mas a Swish mantém valores negativos pequenos.
Melhor desempenho em redes profundas
- O Google demonstrou que a Swish supera ReLU em redes neurais profundas, especialmente no ImageNet.
Geralmente melhora a acurácia
- Experimentos mostraram que modelos como ResNet e MobileNet tiveram ganhos ao trocar ReLU por Swish.
Desvantagens
Mais cara computacionalmente
- Como envolve sigmoid, exige mais cálculos que ReLU.
Nem sempre é melhor que ReLU
- Para redes pequenas ou simples, a diferença de desempenho pode ser insignificante.
Uso:
- Em redes neurais profundas, como ResNet, MobileNet e EfficientNet.
- Em problemas de visão computacional, onde já mostrou vantagens sobre ReLU.
- Quando se quer evitar neurônios mortos sem sacrificar a eficiência.
Tabela Comparativa com funções similares:
Função Equação Características ReLU Simples e eficiente, mas pode causar neurônios mortos. Swish Melhor que ReLU em redes profundas,
suaviza valores negativos.Sigmoid Sofre com vanishing gradient e saturação. Tanh Funciona bem, mas ainda pode saturar. Softsign Suave, menos propensa à saturação que tanh,
mas lenta para valores grandes de .
Exponencial
'exponential'- Equação:
- Faixa de Entrada:
- Faixa de Saída:
- Derivada:
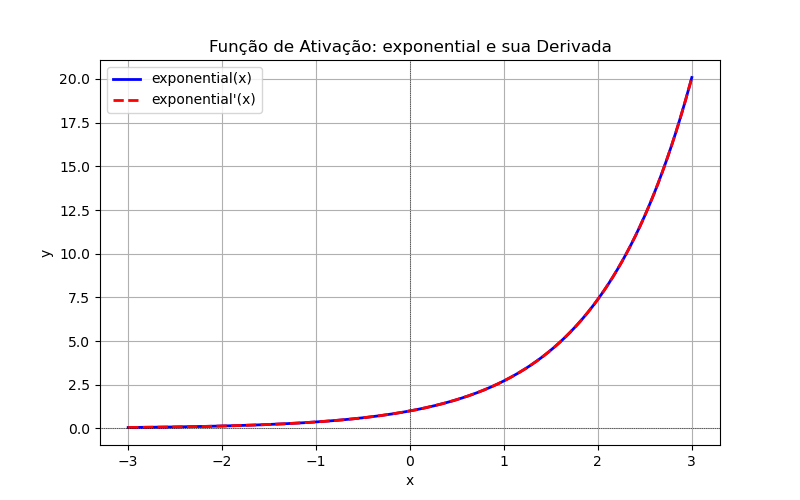
ELU (Exponencial Linear Unit)
'elu': Exponencial Linear UnitEquação:
Faixa de Entrada:
Faixa de Saída:
Derivada:
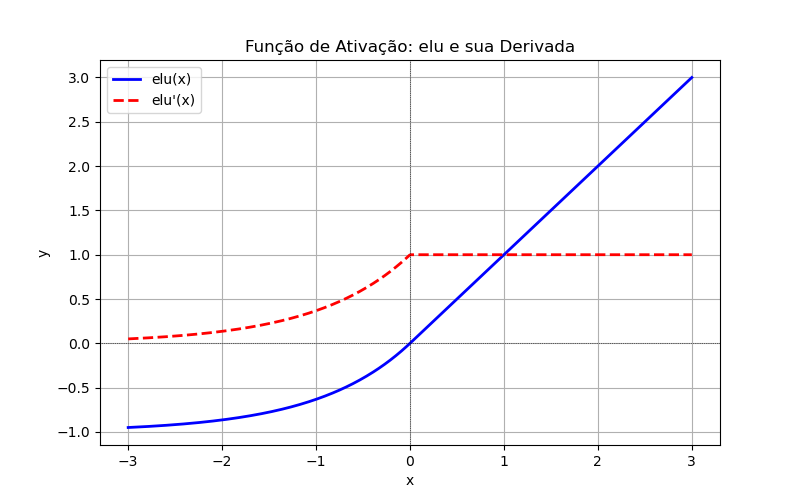
GeLU (Gaussian Error Linear Unit)
'gelu': Gaussian Error Linear UnitEquação: , onde é a função de distribuição acumulada da distribuição normal padrão.
Faixa de Entrada:
Faixa de Saída:
Derivada:
onde é a função de densidade de probabilidade da distribuição normal padrão.
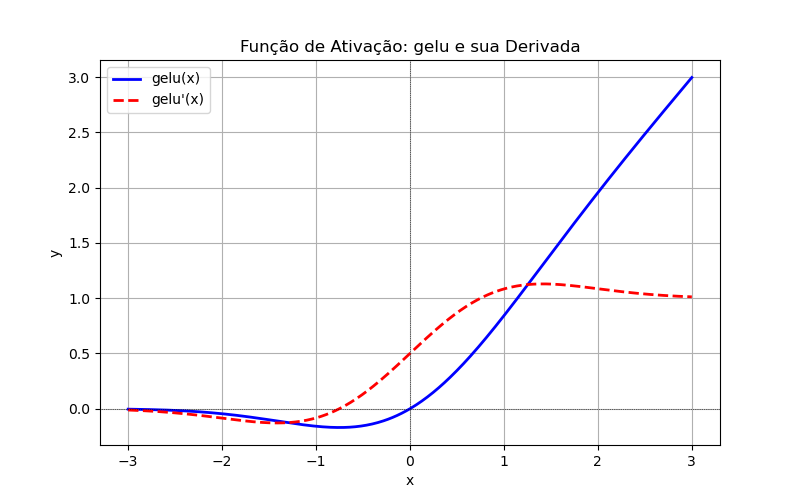
SoftMax
'softmax'!?Equação:
Faixa de Entrada:
Faixa de Saída: , para:
Derivada: A derivada do Softmax é mais complexa e depende da entrada específica. Para uma saída , a derivada parcial em relação a é:
onde é o delta de Kronecker.
A função softmax é bastante usada na camada de saída (a última) para transformar as saídas de uma rede neural em uma distribuição de probabilidade, o que é particularmente útil em tarefas de classificação multi-classe:
- Se for um problema de classificação multiclasse (ex: reconhecimento de dígitos de 0 a 9, detecção de objetos), a última camada deve ter softmax.
- Se for um problema de classificação binária, use
sigmoidem vez desoftmaxna última camada.
Exemplo de uso:
xxxxxxxxxxfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Densemodel = Sequential([ Dense(64, activation='relu', input_shape=(20,)), # Camada oculta com ReLU Dense(10, activation='softmax') # Última camada com Softmax para 10 classes])Outro exemplo:
- O TensorFlow exige que a função softmax seja aplicada em tensores 2D ou superiores. Se for um vetor 1D, o comportamento pode ser inesperado.
xxxxxxxxxximport tensorflow as tffrom tensorflow.keras.activations import softmaxx = tf.constant([1.0, 2.0, 3.0]) # Tensor 1D# Expande para 2D (batch_size=1, features=3), aplica softmax e depois reduz de voltay = softmax(tf.reshape(x, (1, -1)))y = tf.reshape(y, (-1,)) # Converte de volta para 1Dprint(y.numpy()) # Saída correta'''Exemplo de saída gerada:[0.09003057 0.24472848 0.66524094]'''Código para Plotar e
O código abaixo gera um gráfico com a função de ativação ReLU e sua derivada sobrepostas:
xxxxxxxxxximport numpy as npimport matplotlib.pyplot as pltimport tensorflow as tffrom tensorflow.keras import activationsdef plot_activation_function(act_name, x_range=(-3, 3), num_points=500): x = np.linspace(x_range[0], x_range[1], num_points) x_tf = tf.Variable(x, dtype=tf.float32) # Obtém a função de ativação do Keras act_func = getattr(activations, act_name) with tf.GradientTape() as tape: tape.watch(x_tf) y = act_func(x_tf) # f(x) dy_dx = tape.gradient(y, x_tf) # f'(x) # Plot plt.figure(figsize=(8, 5)) plt.plot(x, y.numpy(), label=f'{act_name}(x)', color='blue', linewidth=2) plt.plot(x, dy_dx.numpy(), label=f"{act_name}'(x)", color='red', linestyle='dashed', linewidth=2) plt.axhline(0, color='black', linewidth=0.5, linestyle='dotted') plt.axvline(0, color='black', linewidth=0.5, linestyle='dotted') plt.legend() plt.title(f'Função de Ativação: {act_name} e sua Derivada') plt.xlabel('x') plt.ylabel('y') plt.grid(True) plt.show()# Exemplo: Plotando a função 'relu'plot_activation_function('relu')Explicação
getattr(activations, act_name): Obtém a função de ativação pelo nome.tf.GradientTape(): Calcula a derivada automaticamente no TensorFlow.O gráfico exibe:
- Curva Azul: ( f(x) ) (função de ativação)
- Curva Vermelha (tracejada): ( f'(x) ) (derivada)
Basta chamar plot_activation_function('sigmoid') ou outro nome de ativação do Keras para visualizar diferentes funções.
Saída gerada:
Melhorando o código anterior para outras transfer functions
Segue versão melhorada do código anterior, onde o usuário pode inserir a função de ativação desejada como uma string, garantindo compatibilidade com as funções disponíveis no Keras: show_transfer_function.py
xxxxxxxxxx'''Gera gráfico de f(x) (transfer funtion) e sua derivada, f´(x) -- disponíveis no KerasFernando Passold, em 18/03/2025''' import numpy as npimport matplotlib.pyplot as plt'''As 2 linhas de código abaixo são para suprimiar mensagens do tipo:---2025-03-18 10:38:39.435028: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA---'''import osos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # Oculta avisos e informações do TensorFlowimport tensorflow as tffrom tensorflow.keras import activationsdef plot_activation_function(): act_name = input("Digite o nome da função de ativação (ex: relu, sigmoid, tanh): ").strip().lower() # Lista de funções de ativação disponíveis no Keras available_activations = { 'relu', 'sigmoid', 'tanh', 'softplus', 'softsign', 'selu', 'elu', 'exponential', 'swish', 'gelu', 'exponential', 'linear' #, 'softmax' } if act_name not in available_activations: print(f"Erro: '{act_name}' não é uma função de ativação válida.") print("Funções válidas:", ", ".join(available_activations)) return x_range = (-3, 3) num_points = 500 x = np.linspace(x_range[0], x_range[1], num_points) x_tf = tf.Variable(x, dtype=tf.float32) # Obtém a função de ativação do Keras act_func = getattr(activations, act_name) with tf.GradientTape() as tape: tape.watch(x_tf) y = act_func(x_tf) # f(x) dy_dx = tape.gradient(y, x_tf) # f'(x) # Plot plt.figure(figsize=(8, 5)) plt.plot(x, y.numpy(), label=f'{act_name}(x)', color='blue', linewidth=2) plt.plot(x, dy_dx.numpy(), label=f"{act_name}'(x)", color='red', linestyle='dashed', linewidth=2) plt.axhline(0, color='black', linewidth=0.5, linestyle='dotted') plt.axvline(0, color='black', linewidth=0.5, linestyle='dotted') plt.legend() plt.title(f'Função de Ativação: {act_name} e sua Derivada') plt.xlabel('x') plt.ylabel('y') plt.grid(True) plt.show()# Chama a função para entrada do usuárioplot_activation_function()O que foi alterado?
- Entrada do Usuário: Agora, o usuário pode digitar a função desejada no terminal.
- Verificação da Função: Se o nome digitado não estiver na lista de funções disponíveis, o programa avisa e exibe as opções válidas.
- Atenção ao Case-Sensitivity: O nome da ativação é convertido para minúsculas (
.lower()) para evitar erros de digitação.
Agora, ao rodar o script, ele pedirá a entrada da função de ativação e exibirá seu gráfico com a derivada! 🎨📈
Ocultando mensagens de Warnings no Keras
No meu caso, toda vez que executo o script acima é gerado uma mensagem no início do processamento mostrando algo como:
xxxxxxxxxx2025-03-18 10:38:39.435028: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
É possível evitar essa mensagem de log do TensorFlow ajustando a variável de ambiente TF_CPP_MIN_LOG_LEVEL.
Solução: Suprimir os logs do TensorFlow
Adicione este código logo no início do seu script Python:
xxxxxxxxxximport osos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # Oculta avisos e informações do TensorFlowimport tensorflow as tfExplicação dos Níveis de Log
O TensorFlow usa a variável TF_CPP_MIN_LOG_LEVEL para controlar as mensagens exibidas. Os níveis são:
'0'→ Mostra todas as mensagens (padrão).'1'→ Oculta mensagens de INFO.'2'→ Oculta mensagens de INFO e WARNING.'3'→ Oculta todas as mensagens, incluindo ERROR.
Se quiser esconder apenas as mensagens de otimização da CPU, mas ainda visualizar warnings, use '1' em vez de '2'.
18/03/2025